.jpeg)
.png)
In Part 1, we introduced the idea of using Entropy and VarEntropy to detect hallucinations in the structured outputs of LLM function calls. This post will walk you through how to apply them into a working hallucination detection system. We'll cover the pipeline, what data is needed, how to find the right threshold for your use cases, and use that threshold to catch errors in real time.
Just a quick recap on the uncertainty measures of tokens generated by LLMs..
Entropy: measures uncertainty. In LLMs, it tells us how "sure" the model is about the next token. When the model is confident (e.g., it knows the next token should be <tool_call>), entropy is low. When it’s unsure (e.g., hesitating between get_weather or get_forecast), entropy is high. High entropy means the model is guessing, which could lead to errors.
VarEntropy: goes a step further. Instead of measuring uncertainty at a single token, it tracks how uncertainty changes across a distribution of tokens. If the model’s confidence is steady (e.g., generating a well-structured tool call), VarEntropy is low. If confidence fluctuates (e.g., the model is sure about some tokens but unsure about others), VarEntropy is high. This inconsistency often signals a problem
While both are errors, they stem from different kinds of model failure.
Incorrect Tool Calls (Syntactic & Structural Errors) These are like typos or grammatical mistakes. The model understands the user's intent but fails to generate a syntactically valid function call according to the provided schema.
These errors are often easier to catch with traditional validation methods, like schema validation.
Hallucinations (Semantic & Contextual Errors) These are more deceptive. The generated function call might be perfectly formatted and syntactically valid, but it's factually or contextually nonsensical. The model isn't just making a typo; it's inventing information or misinterpreting the situation.
Our entropy-based detection method is particularly powerful for catching these hallucinations. While schema validators can catch a get_weathr typo, they can't tell if a flight number is real or if a tool call was appropriate in the first place. High entropy, however, can reveal the model's underlying uncertainty as it invents data or makes a questionable decision to call a tool, giving us a signal that something is contextually wrong.
Now, let's explore the robust, two-stage process for building a system to detect these errors.
Step 1: Preparing the dataset
Before you can spot a hallucination, you first need a solid, data-driven understanding of what a correct output looks like. This is the job of a calibration dataset.
The goal of this stage is to map out the typical range of entropy for your model's valid outputs. The great news is that for this step, you don't need labeled hallucinations. You only need a large set of function calls that are verifiably correct. This makes creating the dataset much faster and cheaper.
Here’s the calibration workflow:
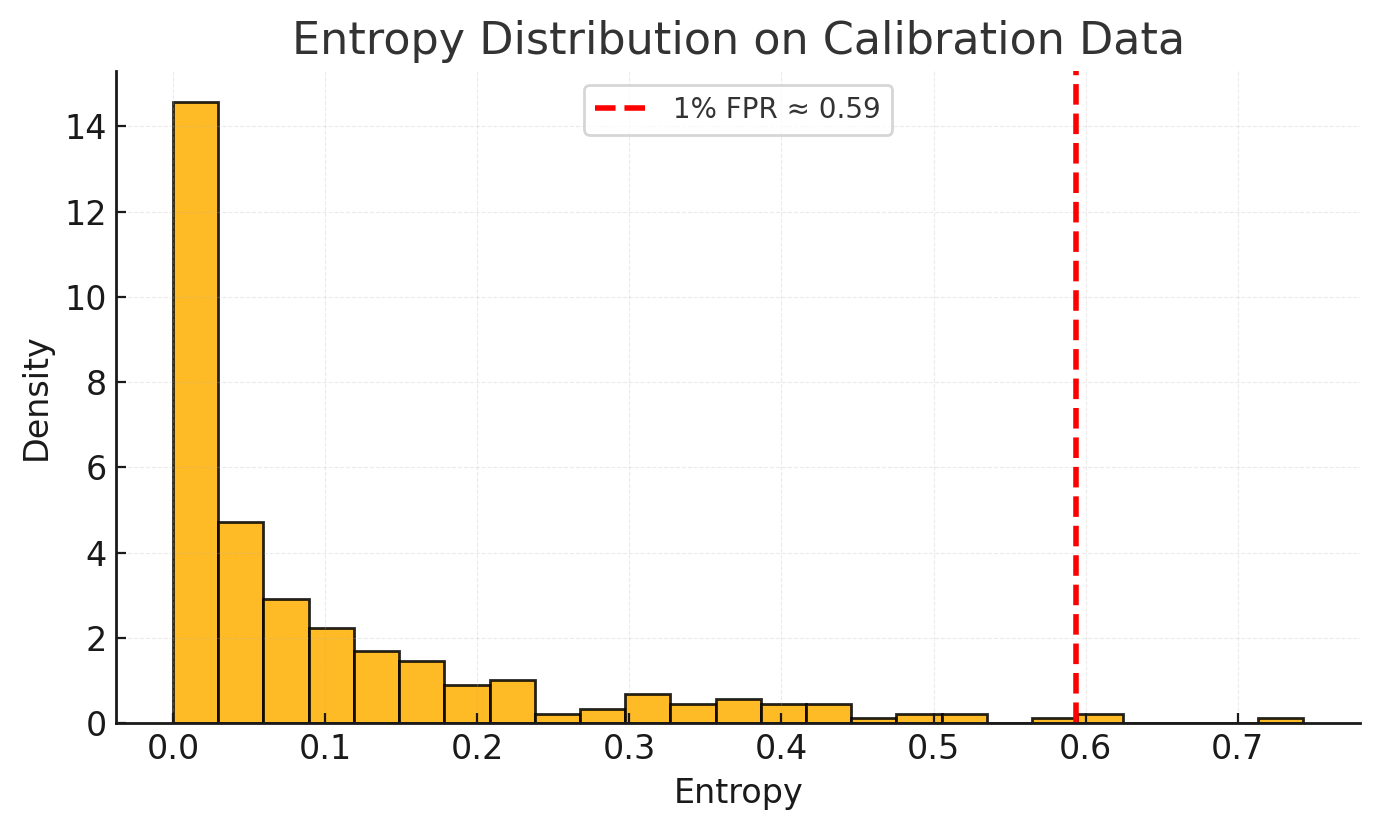
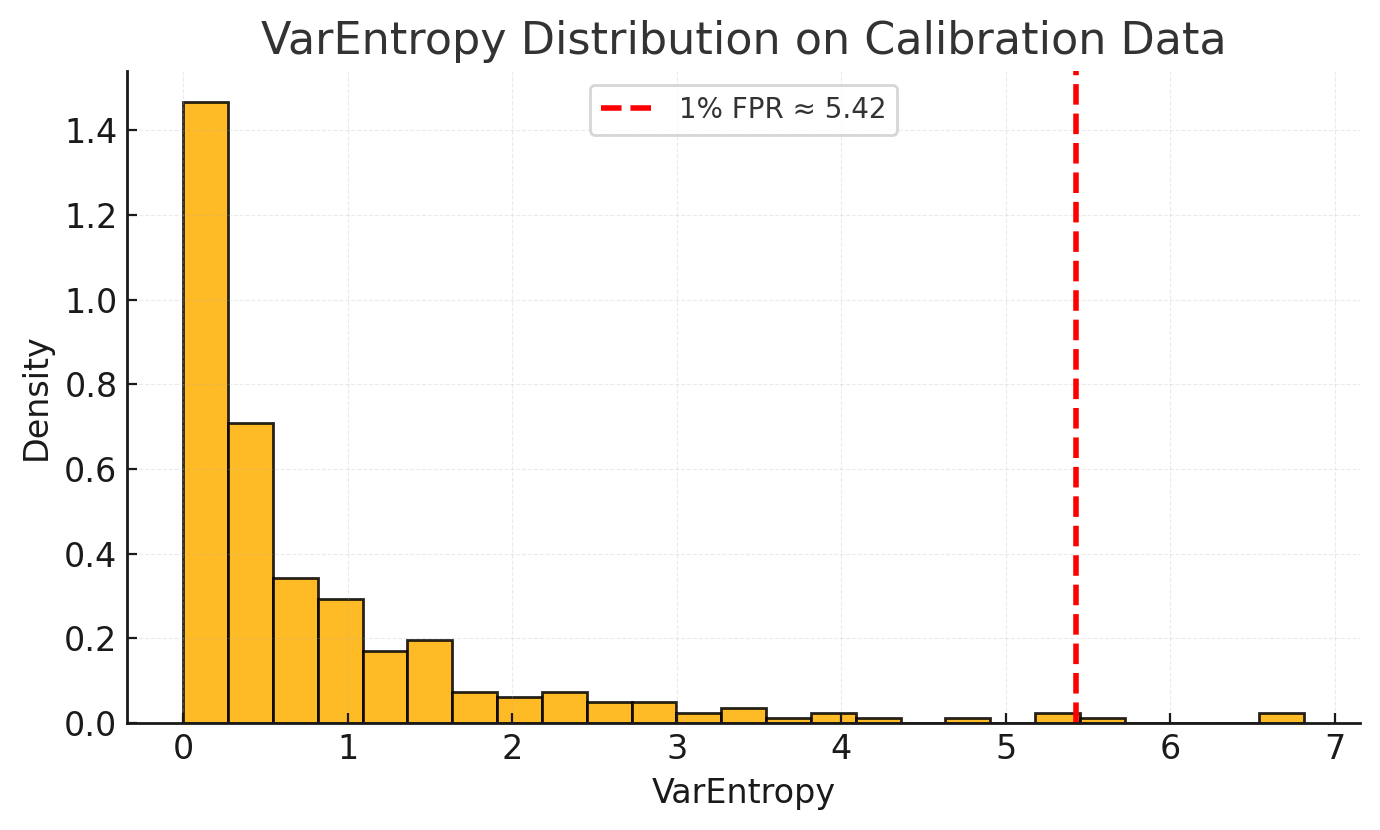
Step 2: Threshold Selection
Now that you have a clear picture of what "normal" looks like, you can set a threshold. Instead of a gut-feeling guess, we'll use a more strategic approach: deciding on an acceptable false positive rate (FPR).
A false positive is when you incorrectly flag a correct function call as an error. You might decide, for example, that an FPR of 1% is a tolerable trade-off for your use case.
Here’s how to set the threshold:
This method gives you direct, explicit control over the rate of false alarms. The final question is: how well does this calibrated threshold actually catch real hallucinations?
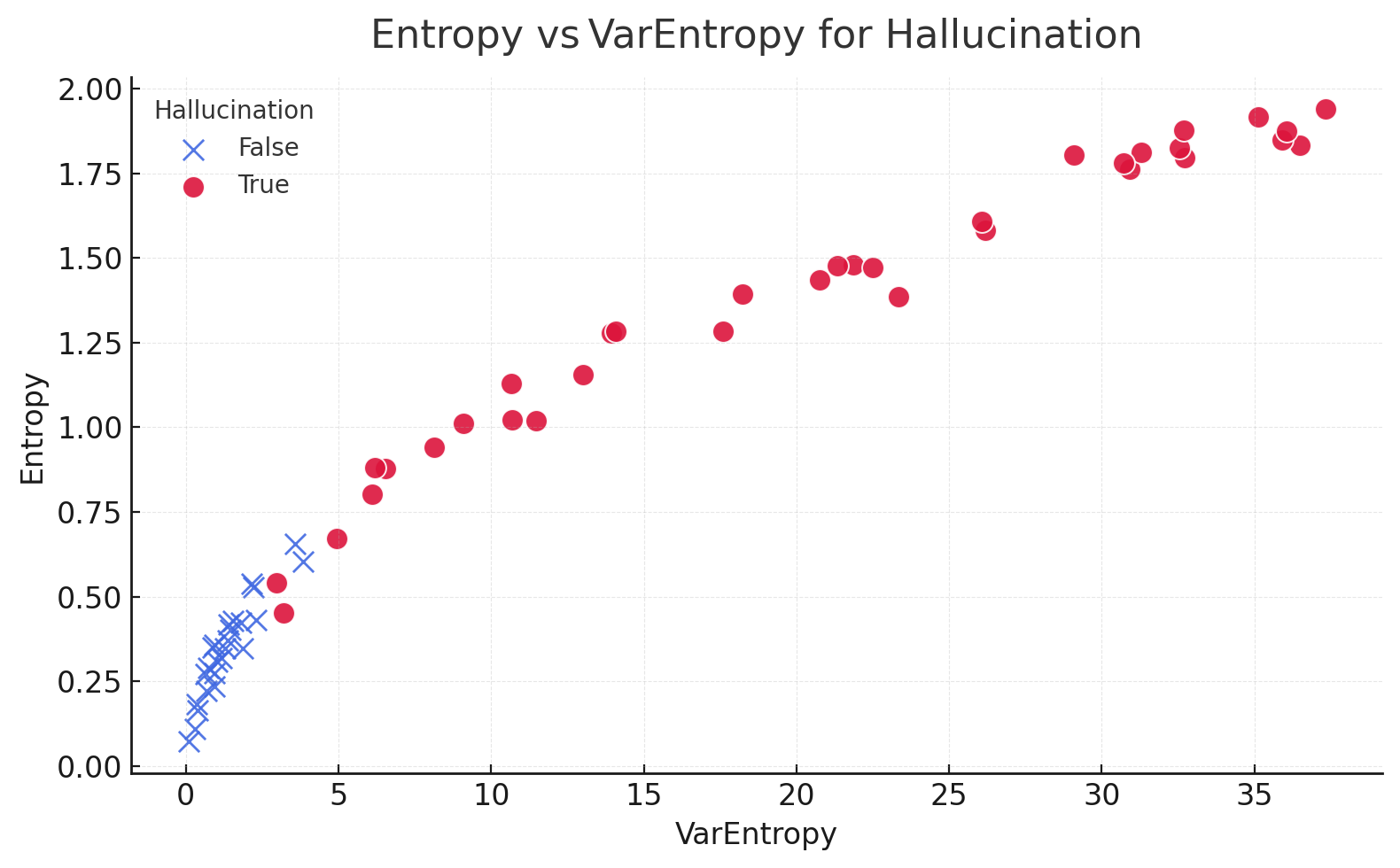
To answer that question, we need an evaluation dataset. This set could be manually labeled or gathered from existing feedback and containing a representative mix of both correct and hallucinated/incorrect calls. While it requires more effort to create, it can be much smaller than the calibration set.
Here's the evaluation process:
Your results will give you a clear performance summary, such as: "A threshold set for a 1% False Positive Rate successfully catches 85% of actual hallucinations." This data allows for an informed discussion about whether that trade-off is right for your application.
By distinguishing between simple errors and true hallucinations, and by using a rigorous calibration/evaluation workflow, you can build a far more effective detection system. This approach elevates your hallucination detection from a heuristic to a reliable, measurable guardrail, allowing you to deploy AI systems with greater confidence.
Everything we walked through—entropy calculation, threshold calibration, and evaluation—has to run inline with your function-calling pipeline if you want to catch hallucinations in real time. archgw uses all of thse techniques: an edge and AI gateway for agents where entropy and varentropy checks are applied before a tool call ever reaches your application logic. If you’re already wiring up tool calls, you can drop archgw in the middle and focus more on the business logic of your agentic apps. And if you find it useful, don’t forget to ⭐ the repo on GitHub.



Arch is an AI-native proxy server that handles all the pesky heavy lifting in building agentic apps -- fast ⚡️ query routing, seamless integration of prompts with business APIs, and unified access and observabilty of LLMs. Built by the contributors of Envoy proxy.